Learning to Solve Soft-Constrained Vehicle Routing Problems with Lagrangian Relaxation
The project was done at Huawei Technologies Co., Ltd., and is vailable on Arxiv.
Tang Q, Kong Y, Pan L, Lee C. Learning to Solve Soft-Constrained Vehicle Routing Problems with Lagrangian Relaxation. arXiv preprint arXiv:2207.09860. 2022 Jul 20.
Paper [PDF]
Motivation
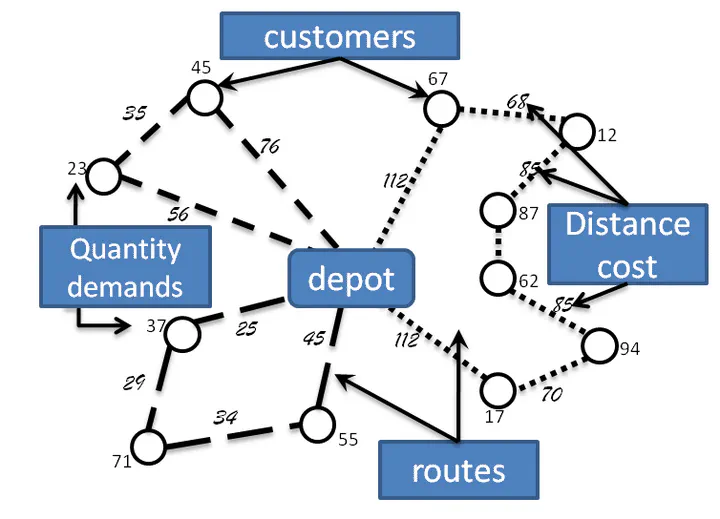
Exact algorithms is not always computationally efficient enough to deploy, especially on large scenarios with complex constraints. Other methods like heuristics or meta-heuristics solvers are also faced with the same dilemma. Vehicle Routing Problems (VRPs) in real-world applications often come with various constraints, therefore bring additional computational challenges to classical algorithms like exact solution methods or heuristic search approaches. The recent idea to learn heuristic move patterns from sample data has become increasingly promising to reduce solution developing costs. However, using learning-based approaches to address more types of constrained VRP remains a challenge.
Trajectory Shaping
We improve the model performance by intervening the trajectory generation process to boost the quality of the agent’s training information. The motivation is similar to modifying the expression of return. Due to the large search space and the sparsity of optima, guiding the agent to explore and learn the ’good’ actions can be very slow or easily trapped into local optima, especially if the initial state solution is far from the true global optimum. With the underlying model being deterministic and we can easily obtain the next state’s reward and cost, we suggest a post-action rejection rule deciding whether to reject the candidate solution respectively when non-improved and improved solutions are found to modify the generated trajectories.

Modified Return
The expression of $G_{t}$ is specially designed to encourage better performance in soft-constrained VRPs with 2-exchange moves. First, the immediate reward is penalized by the immediate cost such that the agent is encouraged to find better moves while balancing the reward and cost with iteratively updated $\lambda$s. In addition, We calculate the cumulative value using the maximum value of all pairs of subsequent moves from $s_{t}$ to $s_{t'}$ instead of a summation over all consecutive moves from $s_{t}$ to $s_{t+1}$ as in the $Return$ definition. “Bad” operations that do not improve the objective function will be suppressed, while only the ‘good’ actions are rewarded with the $\max$ function. It also tends to decorrelate the effect of a series of historical operations so that the agent is less affected by locally optimal trajectories. To sum up, we apply such modification to better mimic the heuristic search process by encouraging more immediate and effective actions that improve the cost-penalized objective function. The following figure provides a visual representation of the definition of $G_t$.


Performance
We observed slightly better performance than Google OR-Tools and close performance to LKH-3.

Concerns on the dataset
Although generation of VRP/CVRP datasets is pretty intuitive, VRPTW datasets are tricky to deal with. In our implementation we generate first a CVRP scenario and then a CVRP solution by heuristics. Time windows are then generated according to arrival time in the CVRP solution to make sure that there is at least one valid sulution. However, we believe that there are better ways to generate VRPTW/CVRPTW datsaets.